uncertainty and partial information
- Learning under uncertainty
- Neurosymbolic verification
- System parameters and uncertainty

-
Sensitivity Analyis
Efficient Sensitivity Analysis for Parametric Robust Markov Chains
- • Sensitivity analysis
- • Parametric robust Markov chains
Have you ever wondered about sensitivity analysis of probabilistic systems? Have you ever thought about measuring sensitivity in terms of the derivative of, say, the expected reward? And are you curious to learn how to use these derivatives for making learning under uncertainty less data-hungry? Well, then we recommend reading our latest CAV paper (Badings et al., 2023).
References
- Badings, T., Junges, S., Marandi, A., Topcu, U., & Jansen, N. (2023). Efficient Sensitivity Analysis for Parametric Robust Markov Chains. CAV.
-
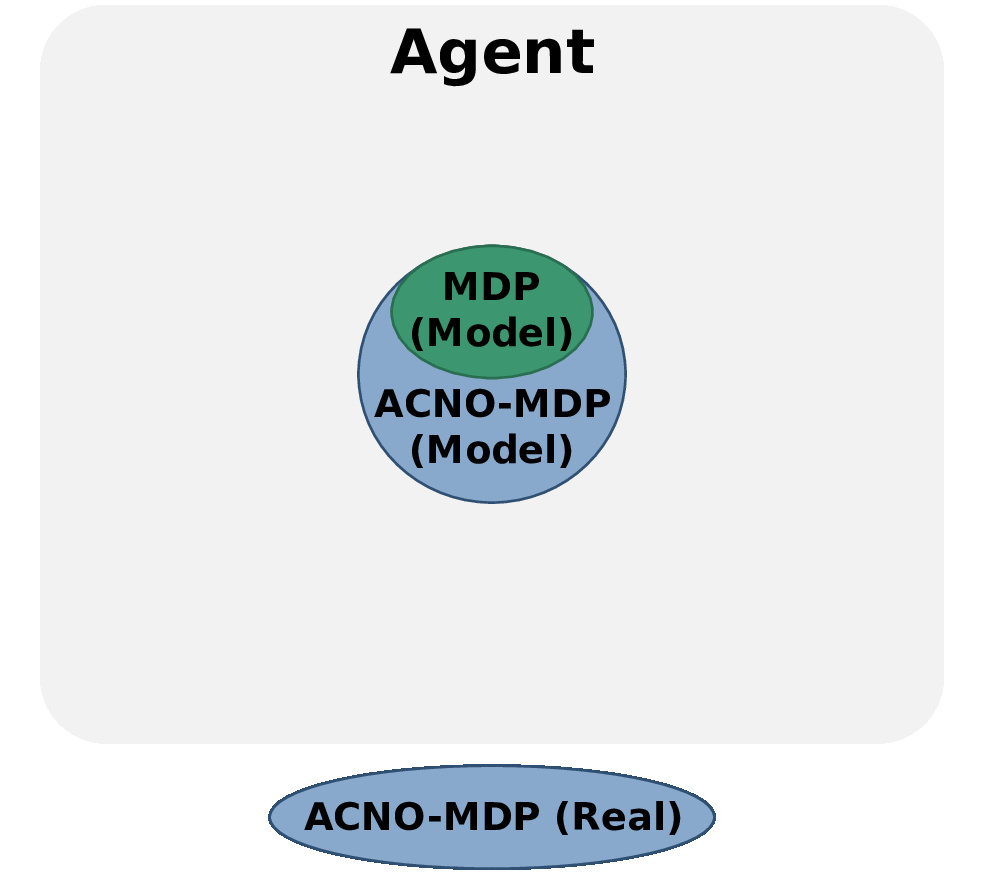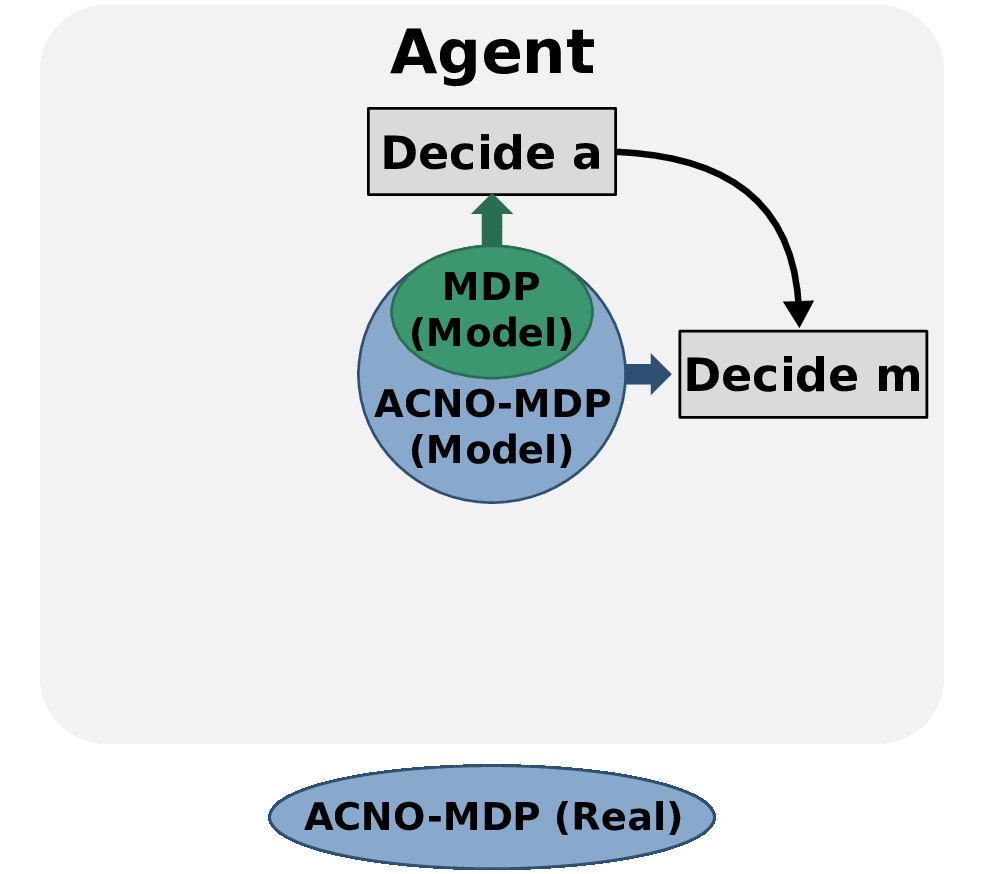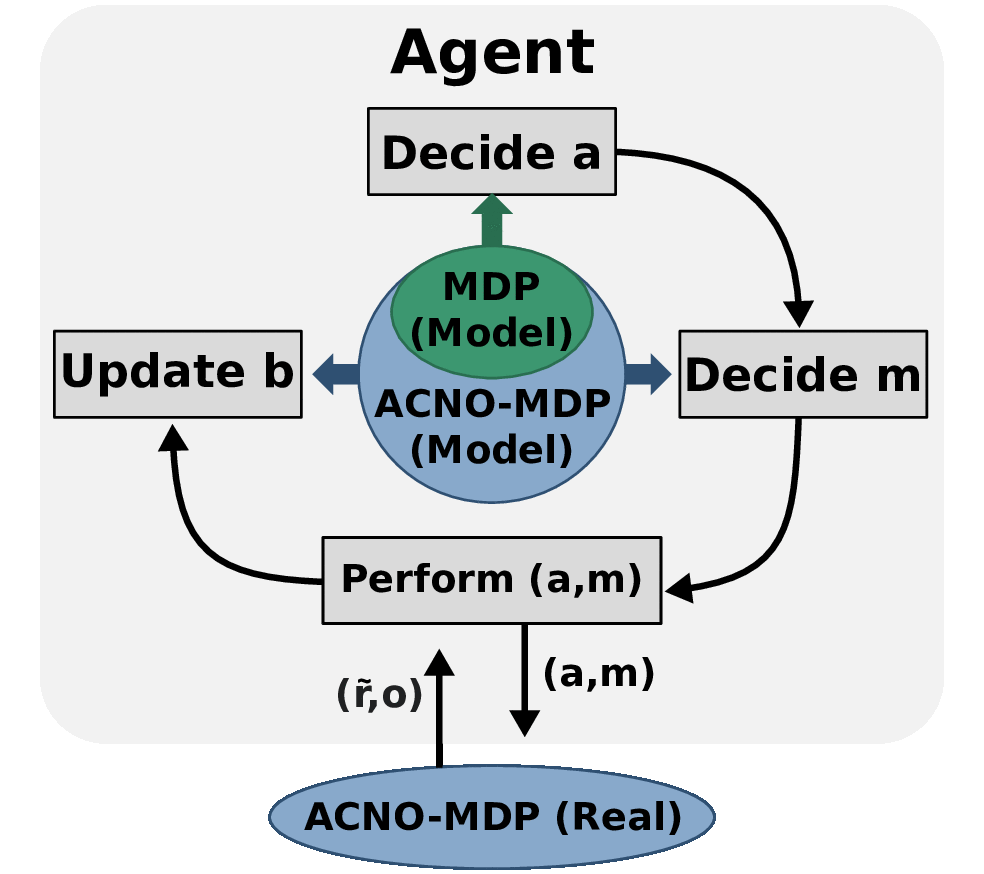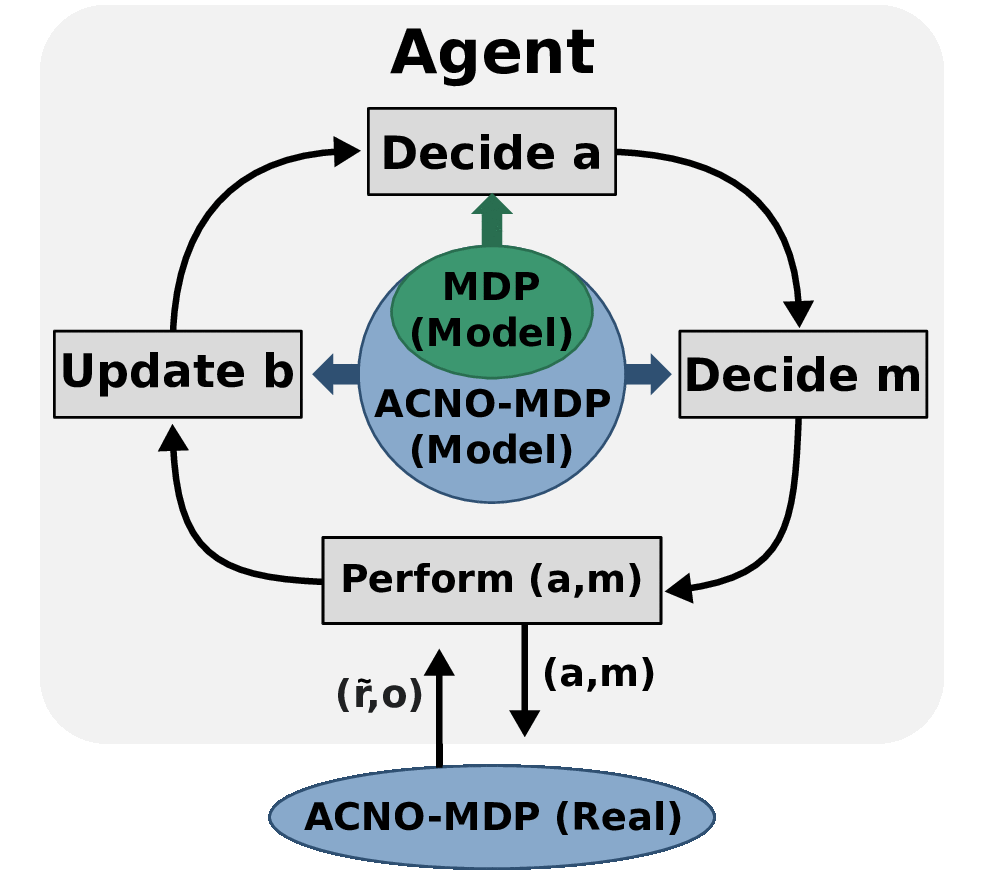
Act-Then-Measure
Reinforcement learning for partially observable environments with active measuring
- • Learning for planning and scheduling
- • Partially observable and unobservable domains
- • Uncertainty and stochasticity in planning and scheduling
Ever wondered when you should inspect the engine of your car? Or how often an electricity provider should check their cables to minimize outages and maintenance costs? Or how often should a drone use its battery-draining GPS system to keep an accurate idea of its positions? What connects these problems is one core question: Is the extra information from a measurement worth its cost?
In our recent work, we try to solve such problems quickly by making a distinction between control actions (which affect the environment) and measuring actions (which give us information). For the first, we take into account uncertainty about the current situation but ignore it when predicting the future, which makes our method faster. For the second, we describe a novel method to determine when we can rely on our predictions, and when we should measure to eliminate uncertainty instead.
Interested in how it performs? Have a look at our ICAPS paper (Krale et al., 2023) to find out!
References
- Krale, M., Simão, T. D., & Jansen, N. (2023). Act-Then-Measure: Reinforcement Learning for Partially Observable Environments with Active Measuring. ICAPS, 212–220.
-

SPI-POMDPs
Reliable offline reinforcement learning (RL) with partial observability
- • Offline Reinforcement Learning
- • Partial Observability
- • Reliability
- • Safety
Limited memory is sufficient for reliable offline reinforcement learning (RL) with partial observability.
Safe policy improvement (SPI) aims to reliably improve an agent’s performance in an environment where only historical data is available. Typically, SPI algorithms assume that historical data comes from a fully observable environment. In many real-world applications, however, the environment is only partially observable. Therefore, we investigate how to use SPI algorithms in those settings and show that when the agent has enough memory to infer the environment’s dynamics, it can significantly improve its performance (Simão et al., 2023).
References
- Simão, T. D., Suilen, M., & Jansen, N. (2023). Safe Policy Improvement for POMDPs via Finite-State Controllers. AAAI, 15109–15117.


